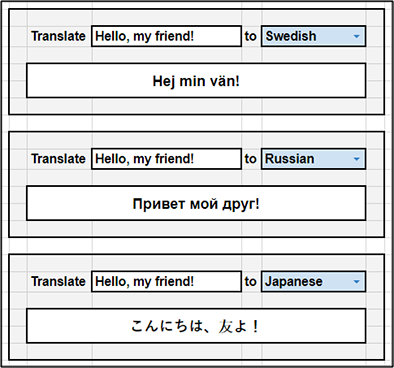
Sayonara CentOS, Hello Replacements.
Since the first public release of CentOS back in 2004, many administrators and tinkerers alike began their journey down the...

Since the first public release of CentOS back in 2004, many administrators and tinkerers alike began their journey down the...
Your website is the beating heart of your business. Whether or not your enterprise operates partly or exclusively through facilitating...
Don’t be afraid to use IPv6, It’s not a whole lot different from IPv4. IPv6 Basics Taking a first look...
[vc_row css=”.vc_custom_1536596414871{margin-bottom: -20px !important;}”][vc_column css=”.vc_custom_1536334899529{margin-bottom: -35px !important;}”][vc_column_text]Many of us work with spreadsheets every day. It’s what allows us to deal...
Introduction to MySQL MySQL Replication using Binary Log File Position, as opposed to Global Transaction Identifiers(GTID), uses binary logs, relay...
If you’re running a Linux server and you value uptime and stability, this server maintenance guide will help keep you...
Docker is a container management platform and is a rather new way of thinking about administration. It’s a tool to...
The Shell… A cloudy mystery for the novice, but an indispensable tool for any seasoned administrator. It is the underlying...
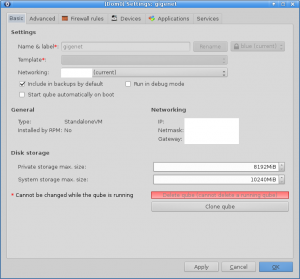
Qubes OS is a distribution of Linux with security as its focus, and it does it very well. At its...
Being a sysadmin is no easy feat, especially for sysadmins working for a hosting provider like GigeNET. They’re tasked with...
I’ve always found peer-to-peer applications interesting. Central points of failure aren’t fun! Protocols like BitTorrent are widely used and well...
It takes a special expert to lead a team of sysadmins for a hosting company. The ideal candidate has extensive...