
This adventure was kicked off by my intent to research an open source supplement or replacement for the enterprise backup solution R1soft ServerBackup. At GigeNET we heavily utilize R1soft, and its API to manage the backups for our fully managed customers. The backup software we have chosen all range in feature set, and complexity.
Here are the 3 best open source backup solutions and how to use them:
R1soft ServerBackup
The R1soft ServerBackup server side installation processes was a very simple process. It involved adding the R1soft repository to CentOS, Debian, or Ubuntu, and just downloading the “r1soft.repo” or “source.list” contents on the website to the correct repository location on the distribution. The next stage of the installation was to pull in the binary from the shell prompt.
On CentOS, we utilized only these two commands:
server@backup# yum install serverbackup-enterprise
server@backup# serverbackup-setup –user DESIRED_USERNAME –pass DESIRED_PASSWORD
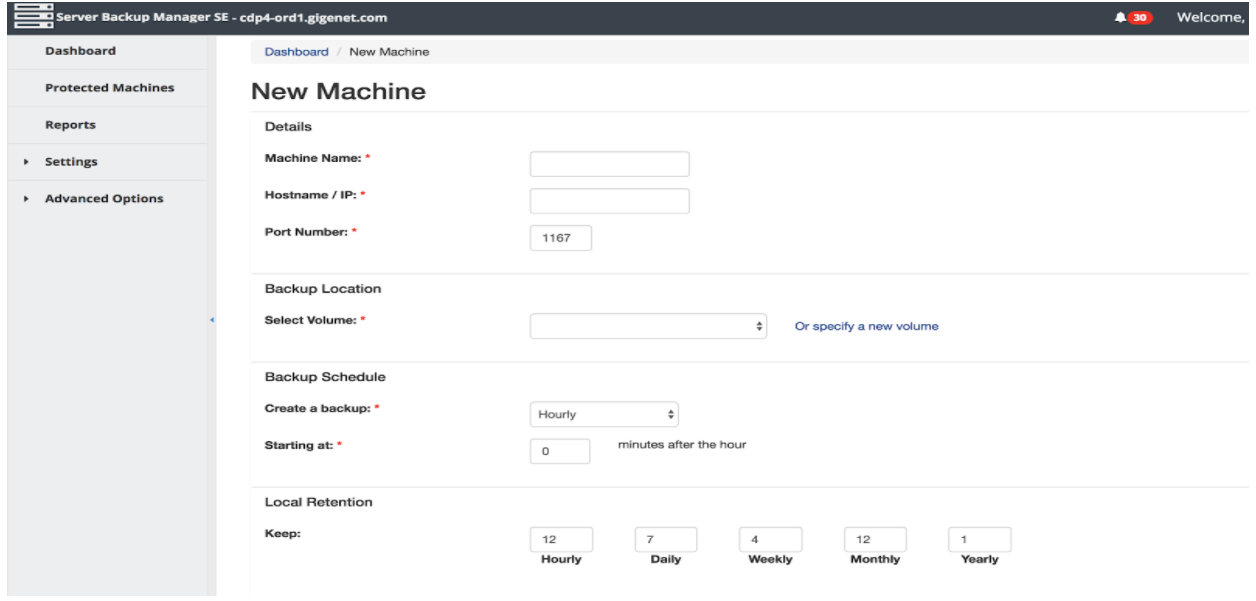
The final stage of the installation process required you to log into the web interface at http://SERVER_IP/. R1soft ServerBackup manages all client machine backup data, and machine configurations through the portal. The design of the portal is very relaxing in terms of navigation. Relaxing because I was able to navigate the entire portal within a few minutes, and I was able to find a simple web form to add a new machine to the backup’s list during this time.
To add a new machine to backup we simply follow this straight-forward form on the web interface:
The client installation process has two methods to be aware of. You can use a built-in client installer through the server-side web interface, which accepts RDP or SSH information. This process is done when adding a new machine through the web interface. The second method requires utilizing the package manager with the “r1soft.repo” or “source.list” in the same manner we described in the server installation process. This installation of the Linux client can be rigorous if the client setup is custom, or the machine is majorly out of date. The client requires a kernel module, and majority of the time this module is pre-built for you. In the situation it’s not prebuilt it will have to be compiled against the kernel. This requires a list of packages installs that can be difficult to obtain if you’re on an older kernel. This also leads to failed builds of the client if the kernel is hardened, or customized outside of what is prepackaged by the operating system.
The install process on CentOS without a module compilation:
client@backup# yum install serverbackup
client@backup# serverbackup-setup –get-module
This is the only block-based backup solution that we have encountered for Linux that doesn’t require a special configuration. The backup solution auto detects the drives, partitions, and ignores the filesystem while performing these backups. This leads to a higher efficiency of performing the backup and provides the ability to do a full bare metal restore. The process allows restoring individual files, entire partitions, and single files. An overall hybrid that can allow you to do complex restores on the bare metal level such as keep the old partition layout or changing the partition layout on the fly.
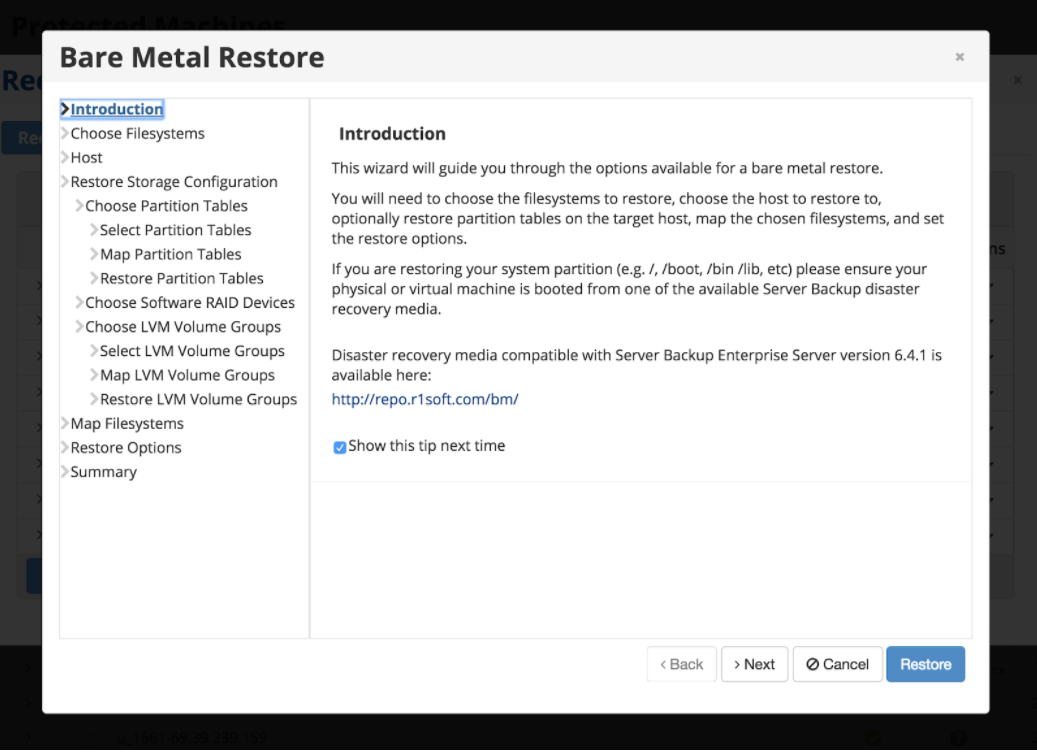
R1soft ServerBackup is an enterprise solution with a very elegant design. However, with complex block-based solutions it does have its drawbacks when it comes to the client. A major issue that we at GigeNET encountered on the server side is that the backup process can lock up on rare occasions. This often leads to failed backups for hundreds of hosts and locks up any new tasks that are queued. The only solution is to restart the service.
Bacula
Bacula is an open source solution that primarily does file-based backups. It also follows the client server model and can backup to various media types. Bacula can utilize tape devices (a feature that was not found with our other solutions I tested). While tape backups might be deemed ancient by some administrators it’s still heavily utilized in larger companies. This is because tape backups can last a decade if stored properly in a salt mine, and there are dedicated companies that have salt “vaults” just for this purpose.
Bacula is installed through the operating systems package manager just like R1soft ServerBackup, but was available without the installation any custom repositories. A minor downside of open source software is that you sometimes are at the whims of the repository maintainers to keep it updated. While you are able to compile the latest stables yourself it generally is a hassle to maintain for smaller teams. The Bacula version that was in Ubuntu, Debian, and CentOS’ repositories defaulted to version 5.1, and the latest stable is the 9.x branch. A minor drawback that I had to come to terms with when utilizing this backup solution. This process it too large to document in this quick overview and would need a dedicated blog in general. Stay tuned for a future blog, or kb article on this topic.
The Bacula server-side backend is overtly complex, and it took me the better part of a day to figure out all of the terminology. I will personally insist that the configuration requires advanced administration skills to follow all of the connections between the director, client, and storage daemons. The director manages all of the backup policies through “jobs, job-defs, schedules, and file-sets” parameters that are dedicated to each individual client. While I understand the complexity is due to its modularity, software designs like these generally just leads to bigger headaches when managing a larger set of systems.
The Bacula client-side configuration was a lot more relaxed. The client is installed through the operating systems package manager with a few short commands. You then alter the “fd” configuration on the client to point back to our Bacula backup director. In the “/etc/bacula/bacula-fd.conf” folder you specify the director with the following lines. The name must consist of a hostname for the backup server.
Below demonstrates this process on a CentOS system:
[client@backup]# yum install bacula-client -y
[client@backup]# systemctl enable bacula-fd
[client@backup]# systemctl restart bacula-fd
In contents of the “/etc/bacula/bacula-fd.conf file.
Director {
Name = BaculaServer-dir
Password = “PASSWORD”
}
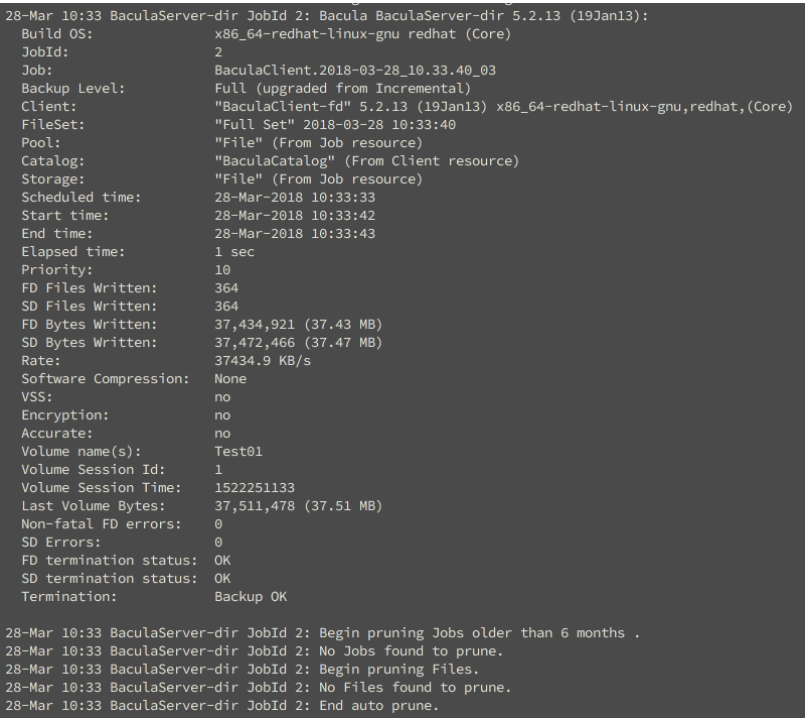
Bacula has a TUI console named “Bconsole” that is utilized to manually manage the backend jobs for each client. This client was straight forward once I learned all of the Bacula component terminologies. You are able to view the current backup jobs, and how they performed in general.
Baculas backup and restore speeds were pretty impressive compared to its competitors. On a setup with utilizing normal spindle devices I saw an average of 50-60MB/s on the file set backups and restores. Other solutions mentioned averaged about 40-50MB/s within the same hardware specification, and configurations. I’ve included a few pictures to show a broad overview of this console below:
Listing clients with the Bconsole:

Listing current jobs that have run:

Listing a more detailed view of the job that ran:
BorgBackup
Borg is a file-based backup utility that doesn’t follow a traditional client-server model. The Borg utility does have a server like component built-in, but it’s more generalized to storing content for the backups. A minor downside to utilizing Borg is that it’s not a complete project. The Borg binary only manages the backups, verifications, and restores. To build Borg into a more complete backup solution we combine the binary with the BorgMatic wrapper written by torsion.org. This wrapper utilizes CronD to schedule backup, perform backup rotations, perform backup verifications, and so forth.
The built-in data deduplication feature on Borg is unique, and it compresses the dataset size on the remote server extensively. Not only does the deduplication help save storage space the compression algorism coincides with the duplication for a more cost saving adventure.
The installation of Borg can be done through python-pip or you can utilize the binary that is statically compiled on the main website located here. The installation process is rather simple when done through pip.
This is the install process on CentOS:
client@backup# pip install borgbackup
client@backup# pip install borgmatic
The backup, file listing, and restore interface can be a little difficult to grasp if you don’t have prior experience with tools like GIT. The closest I can come to describing how the data is segmented is it acts like a GIT repository. The backups are each a branch off of each other based on the last logical backup. Then within each of those branches you can pull data out. The built-in tool allows you to mount each branch with the Linux “FUSE” driver and this is how I generally browsed the backups on Linux. The overall backup process is similar pushing a new branch and merging down the branches when the backup rotation comes into play. I’ve included some live snippets that show the overall design.
Listing the backup’s in a Borg repository:
[client@backup]# borg list /backups
borg1.client-2018-03-27T09:55:34.014081 Tue, 2018-03-27 09:55:39
borg1.client-2018-03-28T09:55:34.014081 Tue, 2018-03-28 09:55:39
Extracting a file from a Borg repository:
[client@backup]# borg extract /backups::borg1.client-2018-03-27T09:55:34.014081 /root/helloworld.txt
Mounting a Borg repository to a folder:
[client@backup]# borg mount /backups::borg1.client-2018-03-27T09:55:34.014081 /mnt/backups
[client@backup]# ls /mnt/backups
[client@backup]# bin boot dev etc home lib lib64 lost+found media mnt opt proc root run sbin srv sys tmp usr var
The biggest drawbacks with Borg is that it’s not really an enterprise ready solution. The lack of a client-server model prevents a more logical approach to machine configuration on a large scale. Borg also does not run as a service and requires a 3rd party wrapper with a CronD to run daily backups. While a cronjob is not a horrible solution it is a step back compared to running the binary as a service. Part of not being enterprise ready steams from the lack of a web interface to manage the backups. While the interface felt similar to GIT and was easy for me to navigate I can see how it would be hard to utilize for an administrator that does not have this experience.
Conclusion
These backup solutions all had their own elegant designs, and feature sets that had me impressed. The open source Bacula solution would not be able to replace R1soft on any scale due to the complexity of the configuration, and the lack of a direct API. The Bacula team does have an enterprise version that is more feature rich. It will be worth exploring after my recent adventures with Bacula.
Then open source BorgBackup solution doesn’t have a direct enterprise solution yet. However, the tool is a wonderful backup solution. The GIT design is very different from the traditional backup solution, and the deduplication is a cost saver when it comes to drive space. Unfortunately, the lack of a client-server model provides us with no direct means of managing the solution on a large scale. A new project has been assembled to resolve these issues, but it doesn’t have a release date. I’ll be watching this very closely.
This subset of backup solutions were not the only solutions we have explored in this adventure. We have also tried out Amanda, UrBackup, and Duplicati. These solutions are all very good in their own nature when it comes to backups, but we had to cut the blog short. I’ll be reviewing these in a future blog post so stay tuned.
Don’t want to do it yourself? Explore GigeNET’s backup services.