
I’ve always found peer-to-peer applications interesting. Central points of failure aren’t fun! Protocols like BitTorrent are widely used and well known. However, there’s something relatively new and uses BitTorrent-like technology, except it’s much more impressive.
What is IPFS?
The InterPlanetary File System (IPFS) is one that caught my eye during research. It’s basically a peer-to-peer, distributed file system, with file versioning (similar to git), deduplication, cryptographic hashes instead of file names and much more. Unlike your traditional file systems that we’ve grown to love, IPFS is very different. It can even possibly replace HTTP.
What’s amazing about IPFS is, for example, if you share a file or site on IPFS the network (anyone else running IPFS) has the ability to distribute that file or site globally. This means that other peers can retrieve that same file or set of files from anyone who cached it. It even can retrieve those files from the closest peer which is similar to a CDN with anycast routing without any of the complexity.
This has the potential to ensure data on the web can be retrieved faster than ever before and is never lost like it has been in the past. A famous example of data loss is GeoCities, a single entity wouldn’t have the ability to shut down thousands of sites like Yahoo did.
I’m not going to get too much into the complexity of what IPFS can do though, there is too much to explain in this short blog post. A good breakdown of what IPFS is and can do, can be found here.
How to install and begin with IPFS
Starting off, I spun up two VMs from GigeNET Cloud running Debian 9 (Stretch). One in our Chicago datacenter and another in our Los Angeles datacenter.
To get the installation of IPFS rolling we’ll go to this page and install ipfs-update, an easy tool to install IPFS with. We’re running on 64bit Linux so we’ll wget the proper tar.gz and extract it. Make sure you always fetch the latest version of ipfs-update!
wget -qO- https://dist.ipfs.io/ipfs-update/v1.5.2/ipfs-update_v1.5.2_linux-amd64.tar.gz | tar xvz
Now lets cd to the extracted directory and run the install script from our cwd (current working directory). Make sure you’re running this with sudo or root privileges.
cd ipfs-update/ && ./install.sh
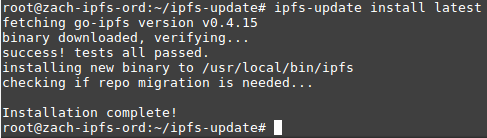
When ipfs-update gets installed (should be very quick) we’ll install IPFS for real with.
ipfs-update install latest
The output should look something like this.
Now that IPFS is installed we need to initialize it and generate a keypair which in turn gives you a unique identity hash. This hash is what identifies your node. Run the following command.
ipfs init
The output should look similar to this.

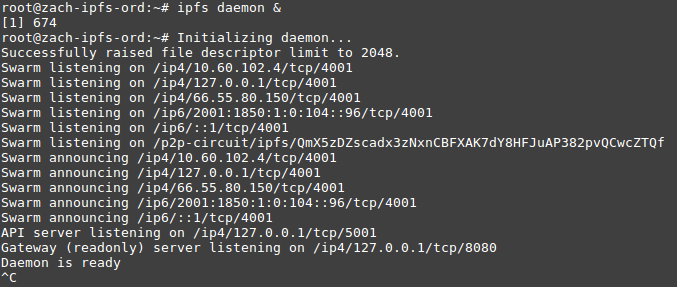
With this identity hash you can now interact with the IPFS network, but first lets get online. This will start the IPFS daemon and send it to the background when you press CTRL + C. It’s probably not advisable to run this as root, or with elevated privileges. Keep this in mind!
ipfs daemon &
Now that we’re connected to the IPFS swarm we’ll try sharing a simple text file. I’ll be adding the file to IPFS which generates a hash that’s unique to that file and becomes its identifier. I’ll then pin the file on 2 servers so that it never disappears from the network as long as those servers are up. People can also pin your files if they run IPFS to distribute them!
Adding and pinning the file on my Chicago VM.

Now that we have the file’s hash from the other VM we can pin it on our VM in Los Angeles to add some resiliency.
![]()
Now to test this we’ll cat the file from the IPFS network on another node!
![]()
That was a pretty simple test, but it gives you an idea of what IPFS can do in basic situations. Overall the inner workings of IPFS are hard to understand, but it is a fairly new technology and it has a lot of potential.
Also, watch that video:
